
PDF Extractor SDK pro vývojáře softwaru Windows: PDF do textu, PDF do XML, Obrázky z PDF, Číst PDF informace, PDF do CSV pro Excel.
Bytescout PDF Extractor SDK umožňuje převést PDF do textu, PDF do XML, PDF do formátu CSV, extrahovat obrázky z PDF, extrahovat informace o souborech PDF v rozhraní .NET a ActiveX bez nutnosti dalšího softwaru.
Výhody:
konvertuje PDF na obyčejný text (a pokud převádíte noviny ve formátu PDF, můžete sledovat sloupce) - včetně extrahování neviditelných textů;
převádí tabulky v PDF do formátu Excel (CSV) čtením buněk z daného obdélníku;
převádí tabulky v PDF do souborů XML;
extrahuje metadata souboru PDF (název, autor, popis) a získá další informace o souboru (počet stránek, šifrované nebo ne);
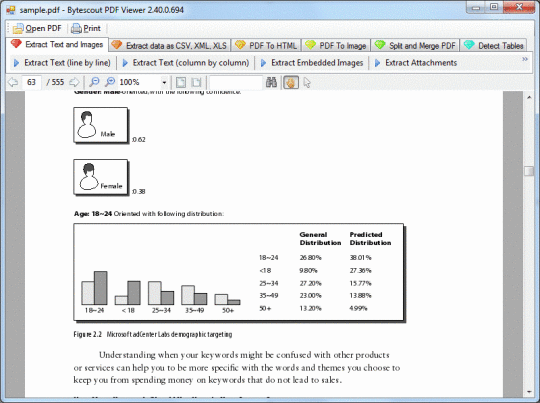
extrahuje vnořené obrázky z dokumentu PDF (v ASP.NET, VB.NET, C #, VB6 a VBScript);
DocumentMerger a DocumentSplitter rozhraní a třídy pro sloučení a rozdělení PDF dokumentů;
nevyžaduje instalaci aplikace Adobe Reader nebo jiného softwaru pro čtení PDF;
poskytuje rozhraní .NET a ActiveX;
vyrobené se 100% spravovaným kódem C #.
Co je nového v této verzi:
Verze 9.0.0.3079: Přidáno filtrování extrahovaného obsahu podle názvu písma, velikosti písma a barvy.
Aktualizovaný nástroj OCR na nejnovější verzi. Aktualizujte jazykové soubory ze složky 'tessdata'.
Vylepšená extrakce textu, seskupení řádků v tabulkových datech, výkon, extrakce formulářů XFA, TableDetector, pevné problémy s analýzou PDF.
Co je nové ve verzi 8.7.0.2980:
Přidáno bylo filtrování extrahovaného obsahu podle názvu písma, velikosti písma a barvy.
Aktualizovaný nástroj OCR na nejnovější verzi. Aktualizujte jazykové soubory ze složky 'tessdata'.
Vylepšená extrakce textu, seskupení řádků v tabulkových datech, výkon, extrakce formulářů XFA, TableDetector, pevné problémy s analýzou PDF.
Co je nové ve verzi 8.6.0.2911:
Přidáno bylo filtrování extrahovaného obsahu podle názvu písma, velikosti písma a barvy.
Aktualizovaný nástroj OCR na nejnovější verzi. Aktualizujte jazykové soubory ze složky 'tessdata'.
Vylepšená extrakce textu, seskupení řádků v tabulkových datech, výkon, extrakce formulářů XFA, TableDetector, pevné problémy s analýzou PDF.
Co je nové ve verzi 8.2.0.2699:
Verze 8.2.0.2699 může obsahovat neurčené aktualizace, vylepšení nebo opravy chyb
Co je nové ve verzi 8.0.0.2528:
Verze 7.0.0.2474:
- byla přidána nová třída nástrojů DocumentPrinter, která umožňuje tisknout PDF dokumenty tiše (bez uživatelských dialogů)
- byla přidána nová třída JSONExtractor
- přidána přepis pro metodu DocumentSplitter.Split (), která umožňuje zadat výstupní složku pro generované soubory
- Opravena chyba s více závity v dokumentu DocumentSplitter
- tableDetector nyní respektuje extrakční oblast nastavenou metodou SetExtractionArea ()
- nové vlastnosti ve třídách extrakce: ExtractionColumns - obsahuje souřadnice nalezených sloupců; CustomExtractionColumns - umožňuje předcházet detekci sloupců
- Metody GetPageRect * nezohlednily rotaci stránky.
Opravena chyba v instalačním programu způsobující některé soubory z předchozí instalace zasahovala do aktualizací - byla provedena kontrola registrace. Nyní knihovna nevyhazuje výjimku, ale pracuje v demo režimu, pokud jste vynechali nebo zadali chybně RegistrationName a RegistrationKey
- PDF Multitool: Přidán poslední seznam dokumentů k tlačítku "Otevřít dokument PDF"
- PDF Multitool: Výběr může být nyní změněn
- Víceúčelový nástroj PDF: přidána funkce Extrahovat JSON
- PDF Multitool: Vylepšený uživatelský tabulkový detektor tabulky
- PDF Multitool: výrazně vylepšená kvalita vykreslování písma
- PDF Multitool: Přidána možnost ladění "Zobrazit detekované sloupce extrakce" do kontextové nabídky pro zobrazení zjištěných sloupců na aktuální stránce. Stane se viditelný pouze po spuštění jakékoli extrakce proti aktuálně zobrazené stránce
- PDF Multitool: Oprava vykreslování písma na 32bitových systémech Windows
- další menší vylepšení a opravy chyb
Co je nového ve verzi 6.30.0.2421:
Version 6.30.0.2421:
- Přidána pomocná třída TextComparer (dostupná pouze v sestavách .NET 4.0), která umožňuje porovnávat text ve dvou dokumentech PDF a vygenerovat přehled.
- Vylepšená podpora barevných profilů ICC
- Zabudovaná manipulace s vloženými písmy
- Vylepšený nástroj AttachmentExtractor.
- Opravena metoda XMLExtractor.SaveXMLToStream ().
- Opravena extrahovaná textová duplikace při použití možnosti OCRCacheMode.WholePage.
- Další opravy a vylepšení chyb.
Co je nového ve verzi 6.20.2354:
Verze 6.20.2354:
- PDF do textu, PDF do formátu CSV, PDF Vylepšené funkce XML
- Nové extrahované video, extrahovat příklady zvuku
- CSV a XML extraktory zlepšily podporu pro tabulky s prázdnými sloupci uvnitř
- nový MultimediaExtractor pro extrahování videa a zvuku z PDF
- nová vlastnost PageDataCaching
- nový příklad "MemoryCareProcessingOfHugeFiles"
- Opravena nulová výjimka při pokusu o odstranění již uložených stránek
- XLSExtractor: zlepšuje podporu písem
- SkipInvisibleText nyní přeskočí oříznutý text (který není viditelný)
- zlepšené vykreslování textového výstupu
- XFDF Extractor: přidána podpora pro zaškrtávací políčka
- Výstupy obrázků se zlepšily, aby podporovaly více subformátů
- Zlepšení správy textů Unicode
Co je nového ve verzi 6.11.2149:
Verze 6.11.2149:
- Dávkové zpracování vzorku aktualizované, aby ukázalo použití metody Reset ()
- Vzorek zdrojového kódu C ++ přidán pro extrakci stránek
- DocumentMerger přidá metodu Merge2 (inputfile1, inputfile2, outputfile) ke sloučení 2 souborů
- Drobné opravy chyb XLS Extractor
- PDF Multitool nyní umožňuje zapnout / vypnout textové, obrazové, vektorové vrstvy, přidá pokročilá nastavení pro extrakci textu
- XML, CSV, extrakce tabulek zlepšuje podporu tabulek s buňkami emtpry ve sloupcích
- Vylepšená vlastnost ExtractShadowLikeText: lepší filtrování pro stínový text
Co je nového ve verzi 6.10.2136:
Verze 6.10.2136:
- PDF do XML, PDF do formátu CSV, funkce PDF do textu se zlepšila
- PDF Příkazový řádek XLS přidán (založený na vbscriptu)
- PDF do SDK ve formátu HTML přidává novou vlastnost .DetectHyperLinks (výchozí hodnota TRUE) povolí nebo zakáže detekci automatických vazeb v textu
- nový SearchablePDFMaker (k dispozici pro licence PRO) pro převod PDF do souborů prohledávatelných PDF
- nové vlastnosti v extraktoru: ConsiderFontNames, ConsiderFontSizes, ConsiderFontColors, ConsiderVerticalBorders v CFG souborech
- detekce sloupců záhlaví (pokud je AutoAlighHeaderToColumns = true) vylepšena
- .DetectLinesInsteadOfParagraphs nahrazen novým .LineGroupingMode, který řídí, jak se řádky sloučí do odstavců
- DŮLEŽITÉ! PDF do XML řeší dlouhotrvající problém s nesprávnou souřadnicí Y pro textové objekty (byl namísto levé dolní místo namísto vlevo nahoře)
- .TableXMinIntersectionRequiredInPercents a .TableYMinIntersectionRequiredInPercents přidány vlastnosti
- Přidaný vzorek kódu C ++
- XML Extractor opravuje chybějící prázdné sloupce v režimu PreserveFormatting = true
- Drobné opravy barev v některých souborech PDF
- Podpora přidávání více jazyků OCR
- PDF Multitool GUI: přidává tlačítko Kopírovat do schránky do dialogů TXT, CSV, XML a rastru vykreslování
- XLSExtractor: přidává vlastnost PageToWorksheet k povolení / zakázání generování samostatných listů na stránku
- nová vlastnost .TextEncodingCodePage
- PDFViewerControl: přidává funkci ValidateContextMenu, která umožňuje uživateli přidat kontextové menu uživatelským položkám
- Ovládání prohlížeče PDF: přidává vlastnosti ShowTextObjects, ShowImageObjects, ShowVectorObjects
- XMLExtractor nyní přidává atribut "OCRConfidence" pro rozpoznaný text
- Funkce kontroly PDF / A (ve verzi beta)
- Zlepšení ovládacích prvků a kontroly textu a zarovnání podle původního rozložení. Problém byl způsoben posunem souřadnic Y v ovládacích prvcích během analýzy: to bylo nesprávné. Správným způsobem je shif ...
- Aktualizovaný XML extraktor: nyní vytváří značku CONTROL pro zaškrtávací políčka a textová pole
- změněn pomocí aktuálního adresáře do adresáře temp
- zaškrtávací políčka, radioboxy, editboxy, komboboxy jsou lépe podporovány
- nyní umožňuje volajícím s částečnou důvěrou
Co je nového ve verzi 5.80.1781:
Verze 5.80.1781:
- Aktualizována funkce PDF do XML, PDF do formátu CSV, PDF do textu
- OCRMode nyní nabízí 9 režimů
- .DetectLineInsteadOfParagraph nyní funguje mnohem lépe. Nastavte jej na hodnotu False a zachyťte víceřádkový text v buňkách tabulky!
- Podpora ovládacích prvků PDF byla vylepšena
- Extrakce dat FDF a XFDF
Co je nového ve verzi 5.10.1747:
- Formáty PDF do XML, PDF do formátu CSV, funkce PDF do textů se zlepšily
- nyní podporuje extrakci textu z textových ovládacích prvků
- Extraktor XML nyní přidává do značek styl písma, velikost, jméno a textové souřadnice
- Ukázka ASP.NET pro přidávání OCR
- nová vlastnost OCRLanguageDataFolder určující umístění složky "tessdata"
- lepší podpora souborů PDF
- zlepšuje podporu otočeného textu
- aktualizované vzorky zdrojového kódu
- aktualizovanou dokumentaci
- drobné vylepšení a opravy
Co je nového ve verzi 5.00.1626:
Verze 5.00.1626:
- Přidána funkčnost OCR (text z obrázků): nyní můžete extrahovat text z vložených obrázků a opravit poškozený text
- problém vyřešen s nástrojem CSV a XML extraktor chybí poslední sloupce s některými nastaveními
- zlepšená podpora poškozených souborů PDF
- Vícenásobné vyhledávací textové vyhledávání s režimy pro shodu slov je nyní podporováno
- nyní můžete hledat text s pomlčkami a na různých řádcích: viz vzorka nového zdrojového kódu Najít text s hypofýzy
- nová vlastnost .RTLTextAutoDetectionEnabled (výchozí hodnota false) pro automatické rozpoznání jazyků RTL
- Ukázka grafického uživatelského rozhraní prohlížeče PDF se zlepšila
- drobné vylepšení a opravy
Požadavky :
strong>:
Nag obrazovka, vodoznak na výstupu
Komentáře nebyl nalezen