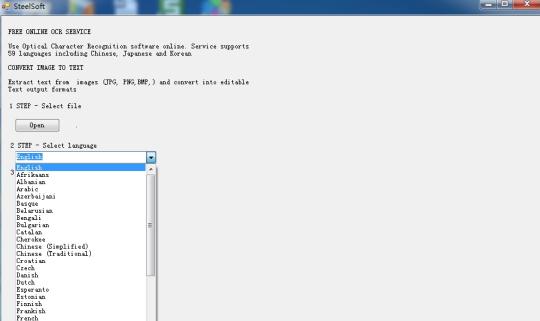
Rozpoznat text z obrázků použitím motoru Tesseract OCR založené na cloud technologii.
Použijte Optical Character Recognition software on-line. Služba podporuje 59 jazyků včetně čínštiny, japonských a korejských. Výpis text z obrázků (JPG, PNG, BMP, TIF), a převést na upravitelný text výstupních formátů.
Je založen na technologii cloud, a velmi slavný OCR motoru (Tesseract OCR Engine), takže je tam jen stovky KB velikost, ale to lze extrahovat text ve 59 jazycích, z obrazů.
To podporuje více jazyků: bulharština, katalánština, čeština, dánština, holandština, angličtina, finština, francouzština, němčina, řečtina, maďarština, indonéština, italština, lotyština, litevština, norština, polština, portugalština, rumunština, ruština, srbština, slovenštině, slovinštině , španělština, švédština, Tagalog, turečtina, ukrajinština, vietnamština etc
Co je nového v této verzi:..
Verze 5.0 obsahuje vylepšení UE


Komentáře nebyl nalezen